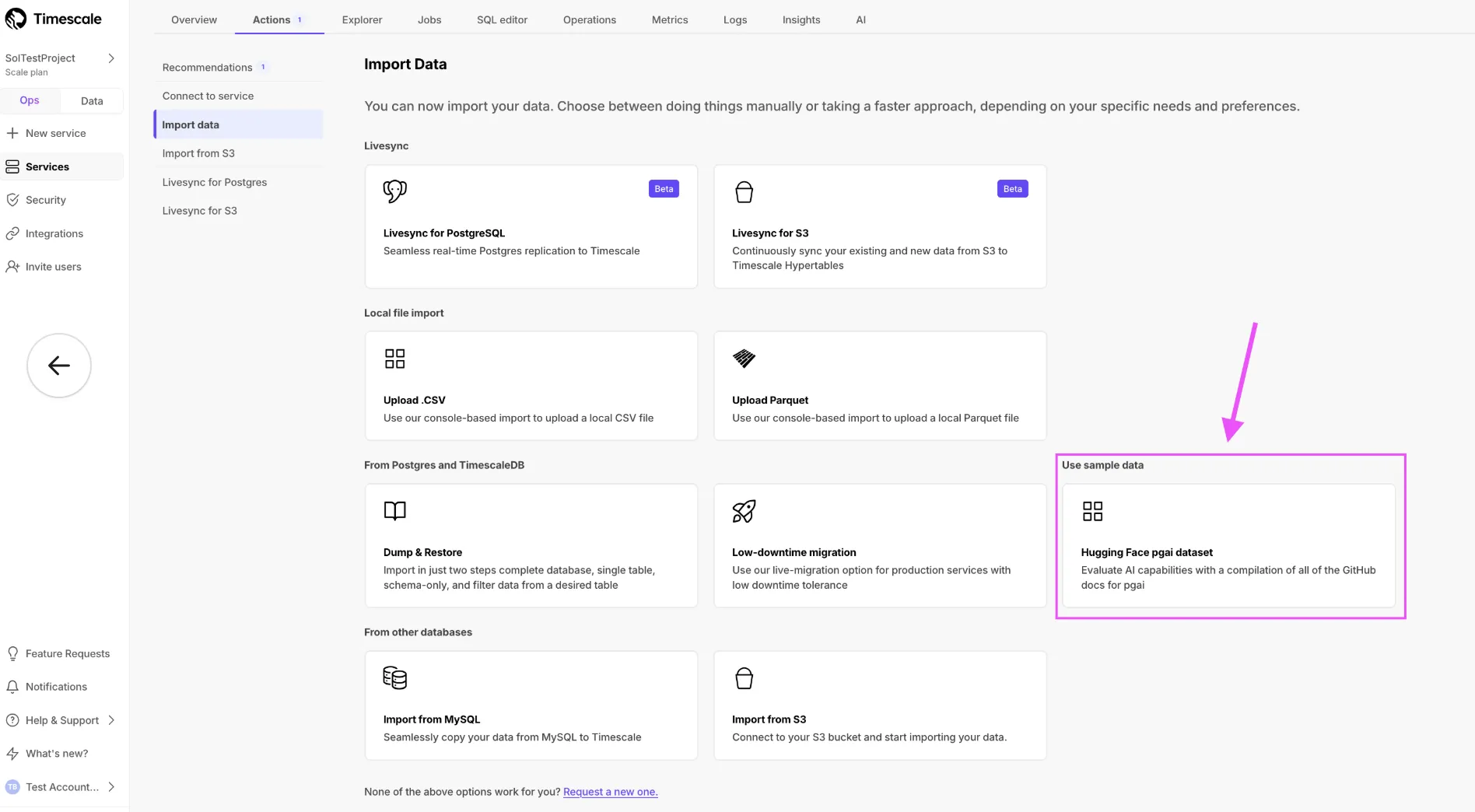
TimescaleDB v2.27 now on Tiger Cloud
TimescaleDB 2.27.0 is a performance-focused release that extends bloom filter pruning into the write path so UPDATE, DELETE, and UPSERT can now skip decompressing batches that can’t match, broadens vectorized execution on the columnstore to cover more analytical query patterns, and introduces an opt-in query rewriter that transparently routes matching queries to existing continuous aggregates. TimescaleDB 2.27.0 was released on May 12, 2026, and is available on GitHub and on Tiger Cloud as of May 19, 2026.
Highlighted features in TimescaleDB v2.27
Section titled “Highlighted features in TimescaleDB v2.27”-
Bloom filter pruning now applies to writes
This release extends bloom filter pruning — previously only used by
SELECT— toUPDATE,DELETE, andUPSERTon compressed chunks.- Bloom filter pruning for
UPDATEandDELETE: Statements with equality predicates now use bloom filters to skip decompressing batches whose compressed rows can’t possibly match. When multiple bloom filters apply, the most selective one (by column count) is tried first. Benchmark examples show up to 160x faster execution on selective workloads.EXPLAINnow reports new “Compressed batches filtered” and “Batches filtered after decompression” counters. - Bloom filter pruning for
UPSERT:UPSERTqueries now leverage bloom filters — including the composite bloom filters introduced in 2.26 — to skip decompressing batches when the arbiter values are guaranteed not to be present. The most selective filter is chosen automatically when multiple apply.EXPLAINadds new statistics for visibility into pruning effectiveness (batches checked, batches pruned, batches without bloom, false positives).
- Bloom filter pruning for
-
More queries on the vectorized columnstore path
This release expands the set of queries that stay on the high-performance columnar execution engine instead of falling back to row-based processing.
- Vectorized filters via the standard PostgreSQL function path: The columnstore engine now supports vectorized evaluation of filters inline through the standard PostgreSQL function path. This broadens the class of queries that can take the fast columnar path — including continuous aggregate refreshes — with benchmarks showing speedups from 30% up to 2x on affected workloads.
- Vectorized aggregation with more
WHEREfilters: Vectorized aggregation now applies in cases where theWHEREclause contains filters not handled through the Vectorized Filters facility, including filters ontime_bucket(). - Scalar array operation pushdown: Predicates of the form
col IN (…)andcol = ANY(…)are now pushed down into the columnar metadata scan asOR/ANDclauses, so each value can be evaluated against compressed-chunk metadata before any rows are expanded.
-
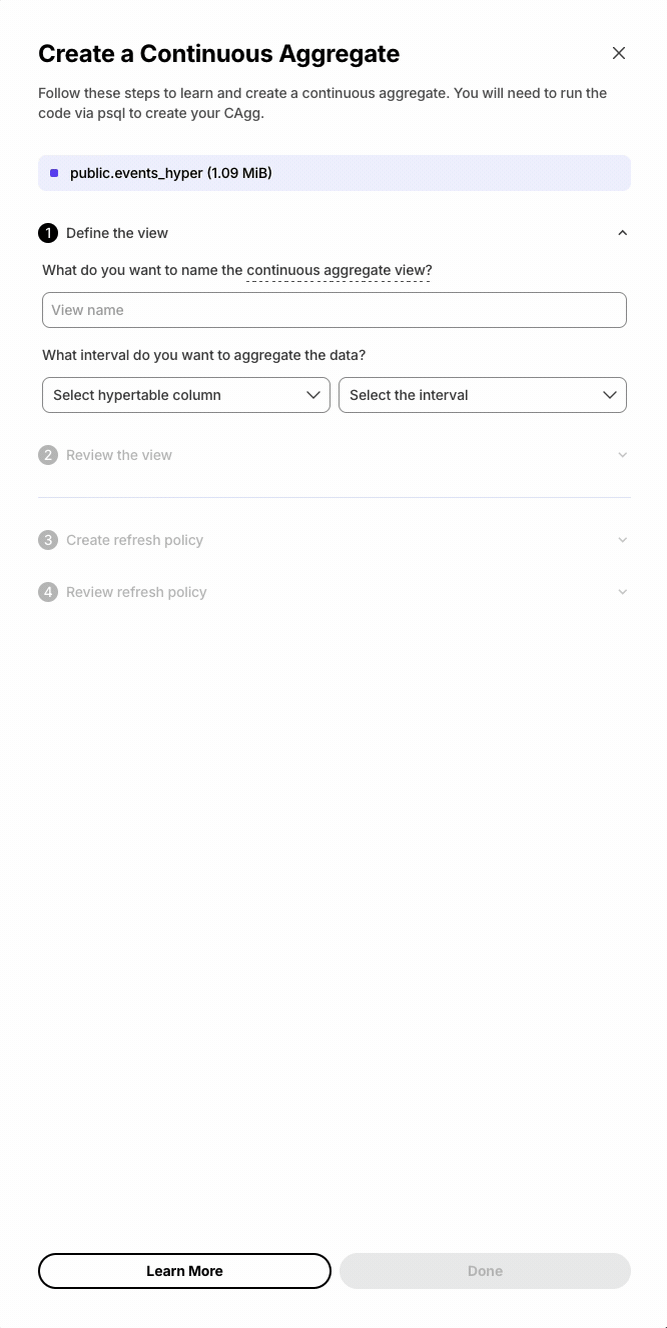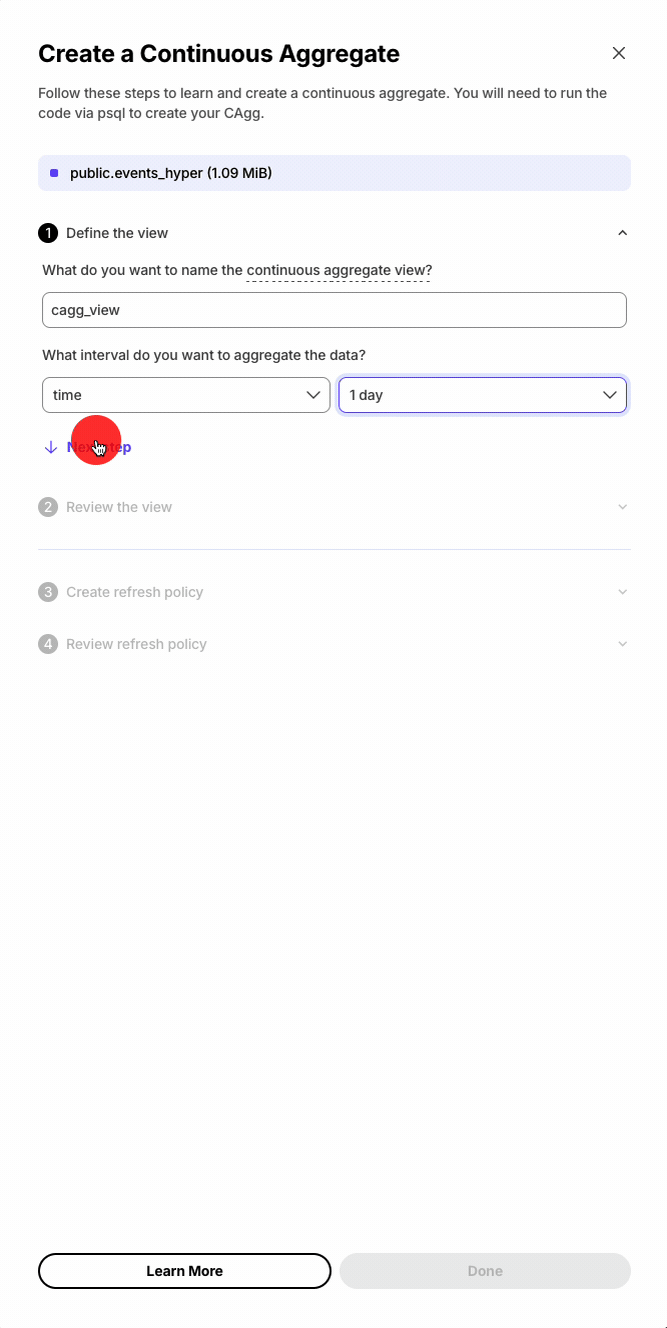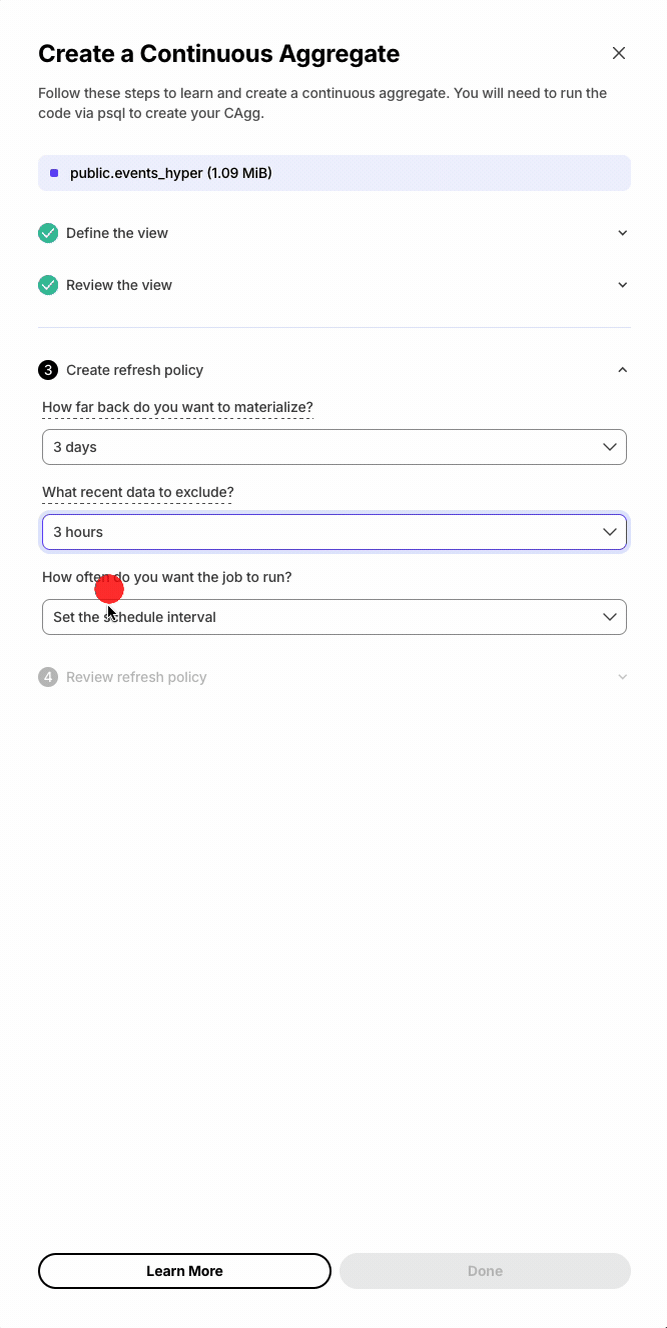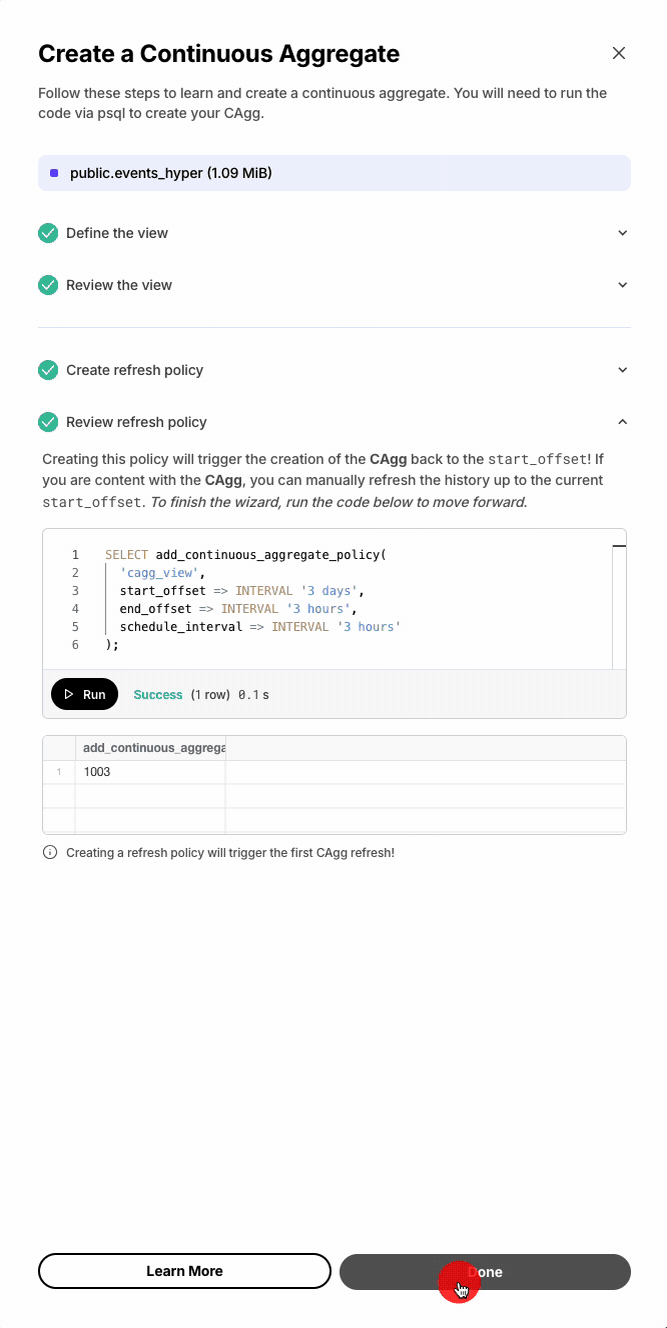
Continuous aggregates
-
Automatic query rewriting with continuous aggregates (experimental, opt-in): A new planner optimization transparently rewrites user queries to use eligible continuous aggregates when the query’s aggregation exactly matches a CAgg’s definition — so applications get pre-materialized performance without referencing the CAgg directly. This feature is experimental in 2.27 and off by default. Only real-time CAggs are eligible, and CAggs with active invalidations or pending materialization ranges are excluded. PostgreSQL 16+ only. Enable with the
timescaledb.enable_cagg_rewritesGUC;timescaledb.cagg_rewrites_debug_infoprints eligibility diagnostics. -
Compress as part of the continuous aggregate refresh policy: The CAgg refresh policy can now compress chunks of the materialization hypertable that fall within the refresh window as part of the same job, consolidating what used to require a separate columnstore policy.
Example:
SELECT add_continuous_aggregate_policy(continuous_aggregate => 'metrics_hourly',start_offset => INTERVAL '30 days',end_offset => INTERVAL '1 hour',schedule_interval => INTERVAL '1 hour',config => '{"compress_after_refresh": true}'::jsonb);
-
-
Smarter chunk exclusion
- Chunk exclusion for
IN/ANYon open time dimensions: Queries that filter the time dimension withINor= ANY(...)clauses now benefit from chunk pruning — the planner derives a bounding min/max range from the values so irrelevant chunks can be excluded earlier. - Faster
ORDER BY … LIMITon more compressed data: Batch Sorted Merge — which returns ordered results from compressed chunks without fully decompressing and sorting them — now applies to chunks with nosegmentby, and to chunks where the query pins everysegmentbycolumn to a constant.
- Chunk exclusion for
-
Quality of life and operability
- Index creation progress reporting: Hypertable index builds now populate PostgreSQL‘s built-in
pg_stat_progress_create_indexview, so long-running builds can be monitored the same way as on plain PostgreSQL. - Automatic
segmentbyfor direct compress: Direct compress now analyzes buffered tuples at flush time to pick an appropriatesegmentbywhen one isn’t explicitly configured, replacing the previous static heuristic. ALTER TABLE … RESETon materialization hypertables: Materialization hypertables now acceptALTER TABLE … RESET (...), in line with regular hypertables.ENABLE/DISABLE TRIGGERon hypertables: Standard PostgreSQL trigger-state commands now work directly on hypertables and propagate to every underlying chunk (includingENABLE ALWAYS,ENABLE REPLICA, andDISABLE TRIGGER USER/ALL).- Notice when compression settings change: A SQL-level notice is now emitted when compression settings change so behavior shifts are visible at run time.
- Index creation progress reporting: Hypertable index builds now populate PostgreSQL‘s built-in
Backward-incompatible changes worth flagging
Section titled “Backward-incompatible changes worth flagging”- A bug in bloom filter sparse indexes on compressed
int2columns could causeSELECTto miss matching rows. Upgrades are blocked for affected databases until the incorrect indexes are dropped manually. - 2.27 uses a new naming convention for composite bloom filter metadata. Queries continue to work, but composite bloom filters created in 2.26 won’t be used until a lightweight, catalog-only migration script renames the legacy columns (no data recompression required).
Upcoming PostgreSQL 15 EOL
Section titled “Upcoming PostgreSQL 15 EOL”As announced in the v2.23.0 changelog on October 29, 2025, the upcoming TimescaleDB release in June 2026 will be the last version supporting PostgreSQL 15. If you are still on PostgreSQL 15, plan an upgrade to PostgreSQL 16 or higher to maintain access to new features, bug fixes, and performance improvements.
For complete details, refer to the TimescaleDB 2.27.0 release notes.